Context quality degrades silently. Your agents start hallucinating, context drifts, and the first alert is a user complaint.
from seer import SeerClient
client = SeerClient()
docs = your_retriever.search(query)
client.log(
task=query,
context=docs,
metadata={"env": "prod"},
)Seer is a production observability platform that evaluates context quality for RAG pipelines, search systems, and AI agents.


Evaluator models score every query for groundedness, recall, and latency so you hear about issues before users do.
Compare new prompts, embeddings, or tool chains against live traffic and ship only when the numbers back it up.
SLA-ready dashboards and alerts that show exactly what went wrong so stakeholder reviews write themselves.
Real-time groundedness and recall scores on every query. Get alerted before users notice.
Learn more →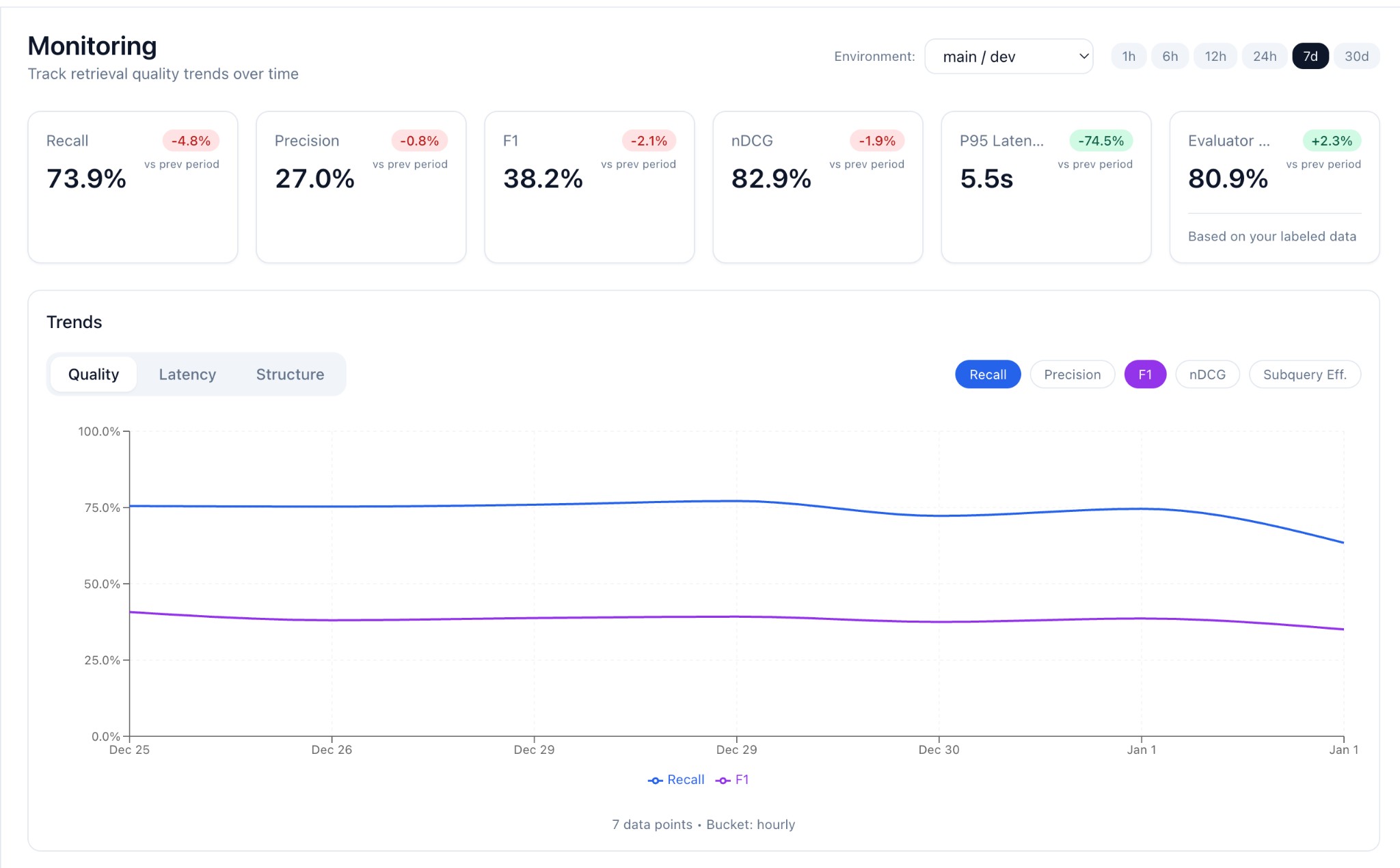
0.87 F1
SOTA level context evaluation accuracy.
40×
Cheaper evaluator inference than GPT-5 for the same coverage.
<5 min
Alerts fire within minutes of regression detection.
5 lines
To integrate Seer into your agent.
Context evaluation accuracy on our benchmark dataset
| Model | Accuracy | Macro F1 | Micro F1 |
|---|---|---|---|
| Seer (Qwen3-4B) Our model | 0.777 | 0.86 | 0.87 |
| GPT-5 | 0.776 | 0.878 | 0.866 |
| GPT-5-chat | 0.750 | 0.865 | 0.848 |
| GPT-5-mini | 0.733 | 0.868 | 0.843 |
| Seer (Qwen3-1.7B) Our model | 0.661 | 0.7633 | 0.7789 |
| GPT-5-nano | 0.628 | 0.721 | 0.752 |
| Qwen3-4B | 0.481 | 0.5104 | 0.539 |
Estimated cost at different evaluation volumes
| Monthly Evals | Seer-4B | Seer-1.7B | GPT-5 | GPT-5-mini | GPT-5-nano |
|---|---|---|---|---|---|
| 100k | $16 | $2 | $606 | $121 | $24 |
| 1M | $160 | $20 | $6,063 | $1,213 | $243 |
| 10M | $1,600 | $200 | $60,625 | $12,125 | $2,425 |
Seer pricing based on hosted inference. Self-hosted options available for enterprise.
Drop the SDK into your retrieval service or agent orchestrator. Send tasks, contexts, and metadata.
Seer grades every query with evaluator models built for groundedness, citation coverage, and latency budgets.
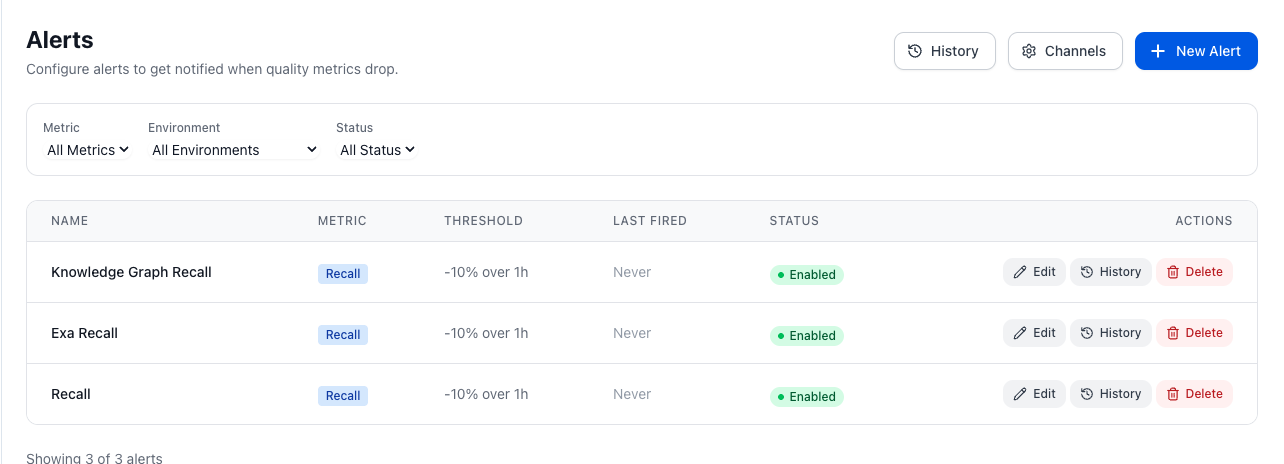
Dashboards, alerts, and CI verdicts close the loop. Ship the winning change and get alerted when drift appears.
Seer is a production observability platform for RAG, search, and AI agent context quality. It scores groundedness, recall, and latency on every query and alerts your team when quality degrades.
Seer uses fine-tuned evaluator models (1.7B and 4B parameters) that assess whether retrieved documents actually answer the query. No manual annotation or labeled datasets required. The models achieve 0.87 F1, matching GPT-5 accuracy at 40x lower inference cost.
Five lines of SDK code in Python or TypeScript. Log your task, context, and metadata. Seer handles evaluation automatically and most teams see their first metrics within 10 minutes.
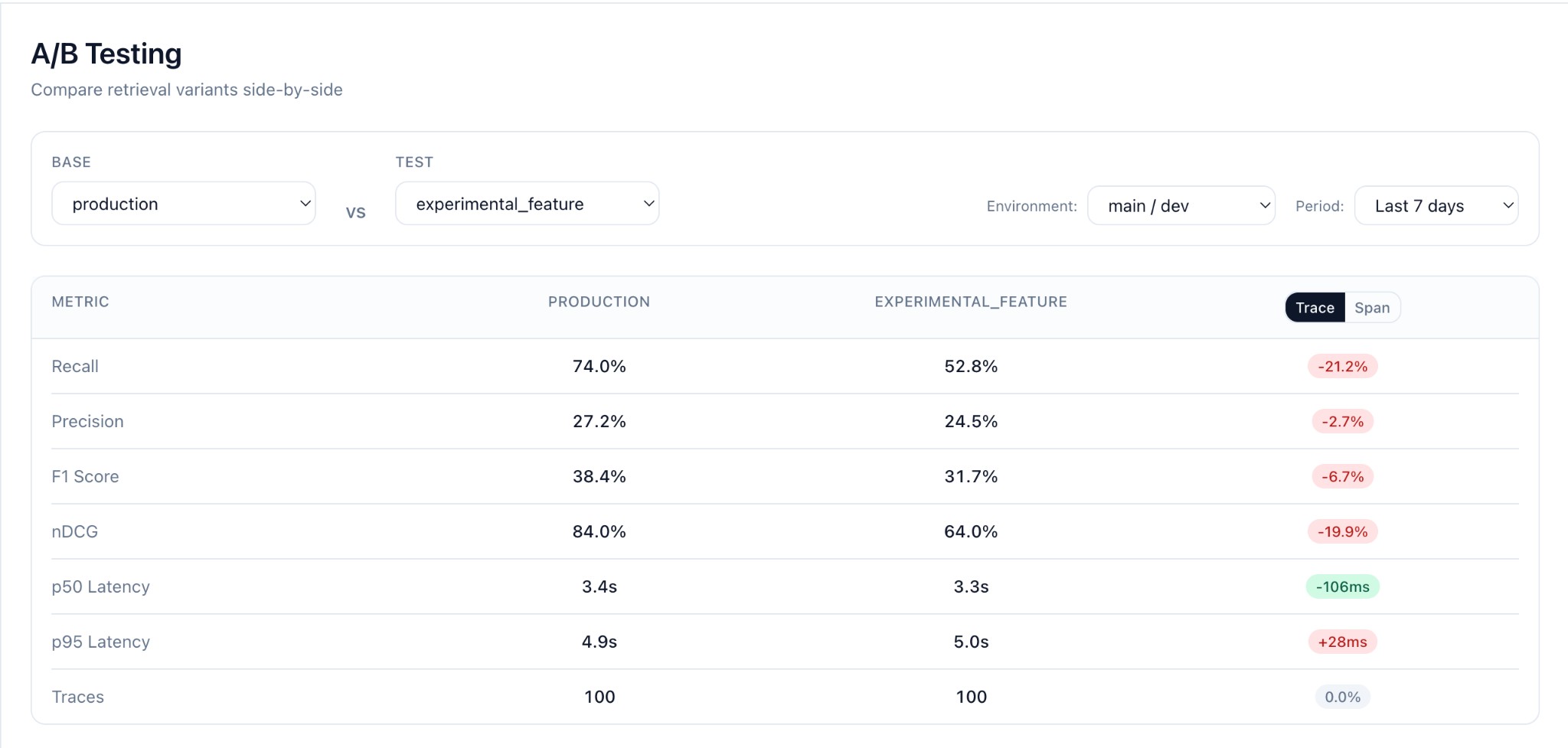
Monitoring tracks context quality continuously in production and alerts you when metrics drop. Change testing compares two retrieval variants (e.g., different embeddings or rerankers) on real traffic and tells you which one wins with statistical confidence.
Seer's evaluator inference starts at $0.00016 per evaluation (4B model) or $0.00002 per evaluation (1.7B model). At 1M monthly evaluations, that's $160/month vs. $6,063/month for GPT-5. Self-hosted options available for enterprise.
Book a walkthrough or jump into the docs. Either way, you get groundedness and recall metrics today.